A Data Warehouse consists of data from multiple heterogeneous data sources and is used for analytical reporting and decision making. Data Warehouse is a central place where data is stored from different data sources and applications.
The term Data Warehouse was first invented by Bill Inmom in 1990. A Data Warehouse is always kept separate from an Operational Database.
If you are intrested to learn big data training please visit:big data online training
The data in a DW system is loaded from operational transaction systems like −
- Sales
- Marketing
- HR
- SCM, etc.
It may pass through operational data store or other transformations before it is loaded to the DW system for information processing.
A Data Warehouse is used for reporting and analyzing of information and stores both historical and current data. The data in DW system is used for Analytical reporting, which is later used by Business Analysts, Sales Managers or Knowledge workers for decision-making.
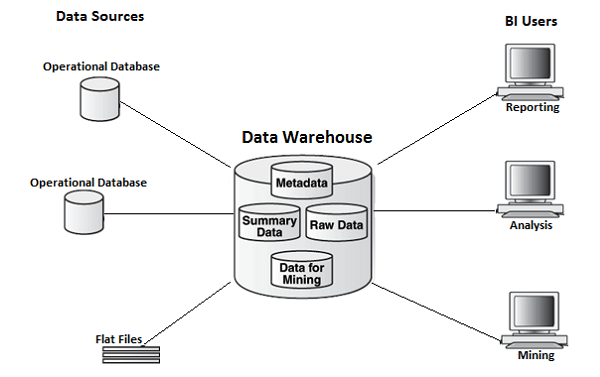
In the above image, you can see that the data is coming from multiple heterogeneous data sources to a Data Warehouse. Common data sources for a data warehouse includes −
- Operational databases
- SAP and non-SAP Applications
- Flat Files (xls, csv, txt files)
Data in data warehouse is accessed by BI (Business Intelligence) users for Analytical Reporting, Data Mining and Analysis. This is used for decision making by Business Users, Sales Manager, Analysts to define future strategy.
Features of a Data Warehouse
It is a central data repository where data is stored from one or more heterogeneous data sources. A DW system stores both current and historical data. Normally a DW system stores 5-10 years of historical data. A DW system is always kept separate from an operational transaction system.
The data in a DW system is used for different types of analytical reporting range from Quarterly to Annual comparison.
Data Warehouse Vs Operational Database
The differences between a Data Warehouse and Operational Database are as follows −
- An Operational System is designed for known workloads and transactions like updating a user record, searching a record, etc. However, Data Warehouse transactions are more complex and present a general form of data.
- An Operational System contains the current data of an organization and Data warehouse normally contains the historical data.
- An Operational Database supports parallel processing of multiple transactions. Concurrency control and recovery mechanisms are required to maintain consistency of the database.
- An Operational Database query allows to read and modify operations (insert, delete and Update) while an OLAP query needs only read-only access of stored data (Select statement).
Architecture of Data Warehouse
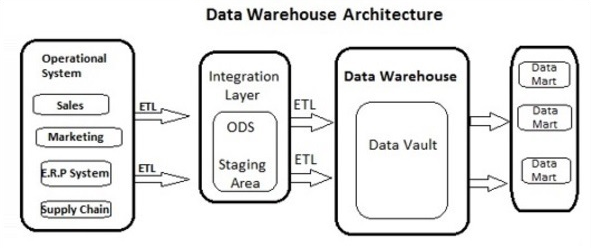
Data Warehousing involves data cleaning, data integration, and data consolidations. A Data Warehouse has a 3-layer architecture −
Data Source Layer
It defines how the data comes to a Data Warehouse. It involves various data sources and operational transaction systems, flat files, applications, etc.
Integration Layer
It consists of Operational Data Store and Staging area. Staging area is used to perform data cleansing, data transformation and loading data from different sources to a data warehouse. As multiple data sources are available for extraction at different time zones, staging area is used to store the data and later to apply transformations on data.
Presentation Layer
This is used to perform BI reporting by end users. The data in a DW system is accessed by BI users and used for reporting and analysis.
The following illustration shows the common architecture of a Data Warehouse System.
Characteristics of a Data Warehouse
The following are the key characteristics of a Data Warehouse −
- Subject Oriented − In a DW system, the data is categorized and stored by a business subject rather than by application like equity plans, shares, loans, etc.
- Integrated − Data from multiple data sources are integrated in a Data Warehouse.
- Non Volatile − Data in data warehouse is non-volatile. It means when data is loaded in DW system, it is not altered.
- Time Variant − A DW system contains historical data as compared to Transactional system which contains only current data. In a Data warehouse you can see data for 3 months, 6 months, 1 year, 5 years, etc.
OLTP vs OLAP
Firstly, OLTP stands for Online Transaction Processing, while OLAP stands for Online Analytical Processing
In an OLTP system, there are a large number of short online transactions such as INSERT, UPDATE, and DELETE.
Whereas, in an OLTP system, an effective measure is the processing time of short transactions and is very less. It controls data integrity in multi-access environments. For an OLTP system, the number of transactions per second measures the effectiveness. An OLTP Data Warehouse System contains current and detailed data and is maintained in the schemas in the entity model (3NF).
For Example −
A Day-to-Day transaction system in a retail store, where the customer records are inserted, updated and deleted on a daily basis. It provides faster query processing. OLTP databases contain detailed and current data. The schema used to store OLTP database is the Entity model.
In an OLAP system, there are lesser number of transactions as compared to a transactional system. The queries executed are complex in nature and involves data aggregations.
What is an Aggregation?
We save tables with aggregated data like yearly (1 row), quarterly (4 rows), monthly (12 rows) or so, if someone has to do a year to year comparison, only one row will be processed. However, in an un-aggregated table it will compare all the rows. This is called Aggregation.
There are various Aggregation functions that can be used in an OLAP system like Sum, Avg, Max, Min, etc.
For Example −
SELECT Avg(salary) FROM employee WHERE title = 'Programmer';
Key Differences
These are the major differences between an OLAP and an OLTP system.
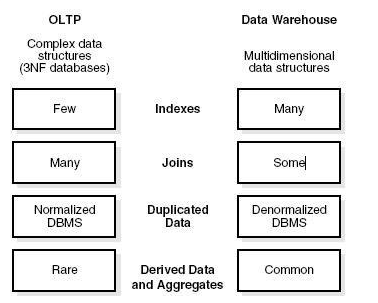
- Indexes − An OLTP system has only few indexes while in an OLAP system there are many indexes for performance optimization.
- Joins − In an OLTP system, large number of joins and data are normalized. However, in an OLAP system there are less joins and are de-normalized.
- Aggregation − In an OLTP system, data is not aggregated while in an OLAP database more aggregations are used.
- Normalization − An OLTP system contains normalized data however data is not normalized in an OLAP system.
Data Mart Vs Data Warehouse
Data mart focuses on a single functional area and represents the simplest form of a Data Warehouse. Consider a Data Warehouse that contains data for Sales, Marketing, HR, and Finance. A Data mart focuses on a single functional area like Sales or Marketing.
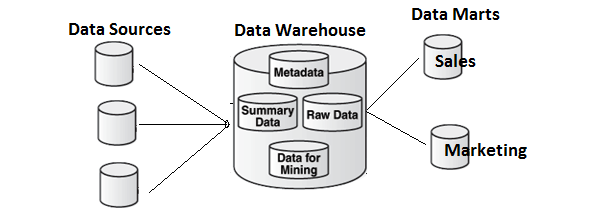
In the above image, you can see the difference between a Data Warehouse and a data mart.
Fact vs Dimension Table
A fact table represents the measures on which analysis is performed. It also contains foreign keys for the dimension keys.
For example − Every sale is a fact.
| Cust Id | Prod Id | Time Id | Qty Sold |
|---|---|---|---|
| 1110 | 25 | 2 | 125 |
| 1210 | 28 | 4 | 252 |
The Dimension table represents the characteristics of a dimension. A Customer dimension can have Customer_Name, Phone_No, Sex, etc.
Data Warehouse – Schemas
A schema is defined as a logical description of database where fact and dimension tables are joined in a logical manner. Data Warehouse is maintained in the form of Star, Snow flakes, and Fact Constellation schema.
Star Schema
A Star schema contains a fact table and multiple dimension tables. Each dimension is represented with only one-dimension table and they are not normalized. The Dimension table contains a set of attributes.
Characteristics
- In a Star schema, there is only one fact table and multiple dimension tables.
- In a Star schema, each dimension is represented by one-dimension table.
- Dimension tables are not normalized in a Star schema.
- Each Dimension table is joined to a key in a fact table.
The following illustration shows the sales data of a company with respect to the four dimensions, namely Time, Item, Branch, and Location.
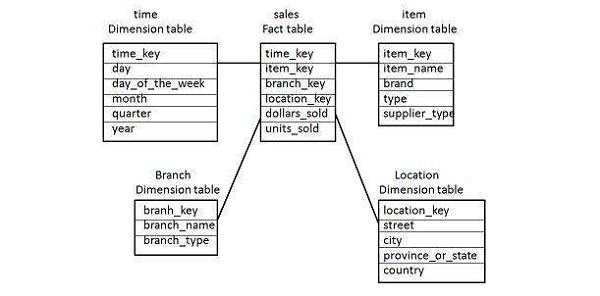
There is a fact table at the center. It contains the keys to each of four dimensions. The fact table also contains the attributes, namely dollars sold and units sold.
Note − Each dimension has only one-dimension table and each table holds a set of attributes. For example, the location dimension table contains the attribute set {location_key, street, city, province_or_state, country}. This constraint may cause data redundancy.
For example − “Vancouver” and “Victoria” both the cities are in the Canadian province of British Columbia. The entries for such cities may cause data redundancy along the attributes province_or_state and country.
Snowflakes Schema
Some dimension tables in the Snowflake schema are normalized. The normalization splits up the data into additional tables as shown in the following illustration.
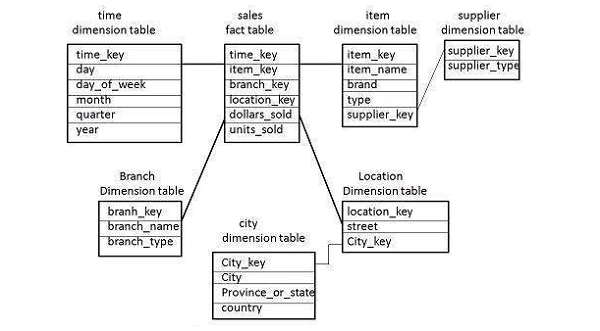
Unlike in the Star schema, the dimension’s table in a snowflake schema are normalized.
For example − The item dimension table in a star schema is normalized and split into two dimension tables, namely item and supplier table. Now the item dimension table contains the attributes item_key, item_name, type, brand, and supplier-key.
The supplier key is linked to the supplier dimension table. The supplier dimension table contains the attributes supplier_key and supplier_type.
Note − Due to the normalization in the Snowflake schema, the redundancy is reduced and therefore, it becomes easy to maintain and the save storage space.
Fact Constellation Schema (Galaxy Schema)
A fact constellation has multiple fact tables. It is also known as a Galaxy Schema.
The following illustration shows two fact tables, namely Sales and Shipping −
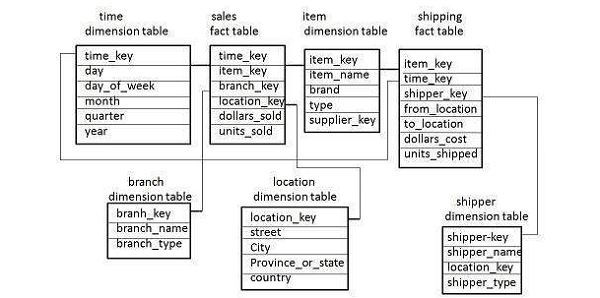
The sales fact table is the same as that in the Star Schema. The shipping fact table has five dimensions, namely item_key, time_key, shipper_key, from_location, to_location. The shipping fact table also contains two measures, namely dollars sold and units sold. It is also possible to share dimension tables between fact tables.
For example − Time, item, and location dimension tables are shared between the sales and shipping fact table.
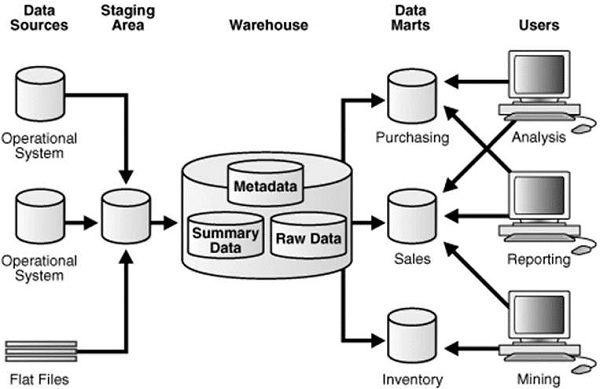
Data Warehouse – ETL & Reporting Tools
An ETL tool extracts the data from all these heterogeneous data sources, transforms the data (like applying calculations, joining fields, keys, removing incorrect data fields, etc.), and loads it into a Data Warehouse.
Extraction
A staging area is required during the ETL load. There are various reasons why staging area is required. The source systems are only available for specific period of time to extract data. This period of time is less than the total data-load time. Therefore, staging area allows you to extract the data from the source system and keeps it in the staging area before the time slot ends.
The staging area is required when you want to get the data from multiple data sources together or if you want to join two or more systems together.
For example − You will not be able to perform an SQL Query joining two tables from two physically different databases.
The data extractions’ time slot for different systems vary as per the time zone and operational hours. The data extracted from the source systems can be used in multiple Data Warehouse Systems, Operation Data Stores, etc.
ETL allows you to perform complex transformations and requires extra area to store the data.
Transform
In data transformation, you apply a set of functions on extracted data to load it into the target system. The data that does not require any transformation is known as a direct move or pass through data.
You can apply different transformations on extracted data from the source system. For example, you can perform customized calculations. If you want sum-of-sales revenue and this is not in database, you can apply the SUM formula during transformation and load the data.
For example − If you have the first name and the last name in a table in different columns, you can use concatenate before loading.
Load
During the Load phase, data is loaded into the end-target system and it can be a flat file or a Data Warehouse system. To learn big data please visit:big data online training india
BI Reporting Tool
BI (Business Intelligence) tools are used by business users to create basic, medium, and complex reports from the transactional data in data warehouse and by creating Universes using the Information Design Tool/UDT. Various SAP and non-SAP data sources can be used to create reports.
There are quite a few BI Reporting, Dashboard and Data Visualization Tools available in the market. Some of which are as follows −
- SAP Business Objects Web Intelligence (WebI)
- Crystal Reports
- SAP Lumira
- Dashboard Designer
- IBM Cognos
- Microsoft BI Platform
- Tableau Business Intelligence
- JasperSoft
- Oracle BI OBIEE
- Pentaho
- QlickView
- SAP BW
- SAS Business Intelligence
- Necto
- Tibco Spotfire ,To more info visit:best online training for big data and hadoop
